Công cụ tìm kiếm hoạt động bằng cách thu thập hàng tỷ trang web thông qua trình thu thập dữ liệu web riêng của chúng, chẳng hạn như GoogleBot hoặc BingBot. Đôi khi chúng được gọi là nhện tìm kiếm hoặc bot. Sau đó, bot tìm kiếm sẽ điều hướng web bằng cách theo dõi các liên kết trên mỗi trang web mới mà nó phát hiện.
Đây là một kiến thức quan trọng mà nhiều SEO mới vào nghề bỏ lỡ:
Nhưng hiểu cách thức hoạt động của công cụ tìm kiếm là điều tối quan trọng!
Tại sao?
Bởi vì bạn cần biết hệ thống hoạt động như thế nào để có thể tận dụng nó! Bạn không thể sửa chữa vấn đề về động cơ ô tô nếu không biết chuyện gì đang xảy ra bên trong động cơ…
… và các quy tắc tương tự được áp dụng cho tất cả các công cụ tìm kiếm.
Tuy nhiên, bạn không cần phải biết mọi thứ về thuật toán của công cụ tìm kiếm.
Tôi sẽ hướng dẫn bạn từng bước cách thức hoạt động của công cụ tìm kiếm.
Hãy bắt đầu với những điều cơ bản của công cụ tìm kiếm để đặt nền tảng cho sự nghiệp SEO thành công.
Cách Google thu thập dữ liệu và xếp hạng các website
Công cụ tìm kiếm Google hoạt động dựa trên hai chức năng chính sau: Thu thập dữ liệu và lập chỉ mục
Chúng ta sẽ xem xét kỹ hơn những điều này sau.
Các công cụ tìm kiếm sử dụng thuật toán tìm kiếm riêng, vì vậy nếu bạn xuất hiện ở vị trí hàng đầu trong trang kết quả của một công cụ tìm kiếm thì không nhất thiết có nghĩa là bạn sẽ xuất hiện ở các công cụ tìm kiếm khác như Bing….
Một số người tập trung nhiều vào chất lượng nội dung, số khác tập trung vào trải nghiệm người dùng và số khác nữa tập trung vào xây dựng liên kết.
Hiểu được những gì công cụ tìm kiếm muốn là yếu tố then chốt cho sự thành công của bạn trên SERP. Chúng ta sẽ xem xét kỹ hơn vấn đề này sau.
Nhưng hiện tại, hãy hiểu rằng: Google là người tiên phong trong nhiều kỹ thuật mà bạn sẽ thấy trong hướng dẫn này. Họ chiếm 92,37% thị trường công cụ tìm kiếm toàn cầu.

Như bạn thấy, Google thống trị thế giới công cụ tìm kiếm. Nhưng công cụ tìm kiếm mà chúng ta đều biết và yêu thích này hoạt động như thế nào?
Trên thực tế, nó khá đơn giản và diễn ra theo quy trình 2 giai đoạn
- Thu thập dữ liệu: Đầu tiên, Google “thu thập dữ liệu trên web” để tìm các trang để thêm vào cơ sở dữ liệu của họ.
- Lập chỉ mục: Sau đó, kết quả được sắp xếp hoặc “lập chỉ mục” và thêm vào cơ sở dữ liệu của chúng.
Ở mức độ cơ bản, hãy nghĩ về việc ai đó đang tạo ra một thư viện sách khổng lồ.
- Thu thập thông tin là tìm kiếm những cuốn sách mới để thêm vào thư viện.
- Lập chỉ mục là sắp xếp những cuốn sách bạn có theo thứ tự cụ thể (như thể loại hoặc tác giả).
Sự khác biệt duy nhất giữa thư viện và Google là Google có hàng tỷ cuốn sách.
Crawl dữ liệu là gì?
Khi bạn nhập truy vấn tìm kiếm vào công cụ tìm kiếm, bạn có thể cho rằng Google đang tìm kiếm trên toàn bộ trang web vào thời điểm đó.
Điều thực sự xảy ra là trình thu thập thông tin của công cụ tìm kiếm đã biên soạn một cơ sở dữ liệu khổng lồ về các trang web và bạn đang tìm kiếm trong cơ sở dữ liệu đó, KHÔNG PHẢI toàn bộ mạng lưới toàn cầu. Cơ sở dữ liệu này bao gồm các trang web đã được Google phê duyệt trước và được Google đánh giá là an toàn cho người dùng. Vì vậy, bạn sẽ không tìm thấy bất kỳ nội dung đáng ngờ nào từ “web đen” cho truy vấn tìm kiếm của mình khi sử dụng Google.
Tại sao Google lại làm như vậy?
- Nó có thể truy cập cơ sở dữ liệu này một cách đáng tin cậy
- Nó cung cấp trải nghiệm nhanh hơn và thân thiện hơn với người dùng
- Nó cho phép Google thêm “thẻ” của riêng mình vào các trang này và cung cấp kết quả có liên quan
Giai đoạn đầu tiên trong việc thêm các trang vào cơ sở dữ liệu này được gọi là thu thập thông tin. Google có các “trình thu thập thông tin” (hoặc “nhện” ) được sử dụng để quét internet.
Những trình thu thập dữ liệu web này có 2x công việc:
- Tìm các trang web mới để lập chỉ mục
- Thu thập thông tin về từng trang web
Trình thu thập thông tin hoạt động như thế nào?
Tất cả các trang web đều là một phần của mạng lưới gọi là World Wide Web, về cơ bản giống như một mạng nhện khổng lồ trải dài khắp thế giới.
Sự khác biệt duy nhất là mạng lưới toàn cầu được kết nối với nhau bằng các liên kết (còn gọi là siêu liên kết hoặc liên kết ngược ). Và trình thu thập thông tin của công cụ tìm kiếm (hay còn gọi là nhện) sử dụng những liên kết này để di chuyển khắp web và khám phá nội dung mới!
Khi trình thu thập thông tin web tìm thấy một trang mới, chúng sẽ bắt đầu đọc toàn bộ nội dung và mã của trang đó.
Trong thế giới lý tưởng, chúng ta muốn mã càng dễ hiểu càng tốt để Google có thể diễn giải và hiểu được. Đó chính là lúc chủ sở hữu trang web sẽ thực hiện SEO (tối ưu hóa công cụ tìm kiếm).
Quá trình thu thập dữ liệu không phải do con người thực hiện và mỗi trình thu thập dữ liệu web hoạt động tự động (sử dụng máy học từ thuật toán của công cụ tìm kiếm ) để quyết định xem các trang chúng tìm thấy có nên được thêm vào chỉ mục của Google hay không.
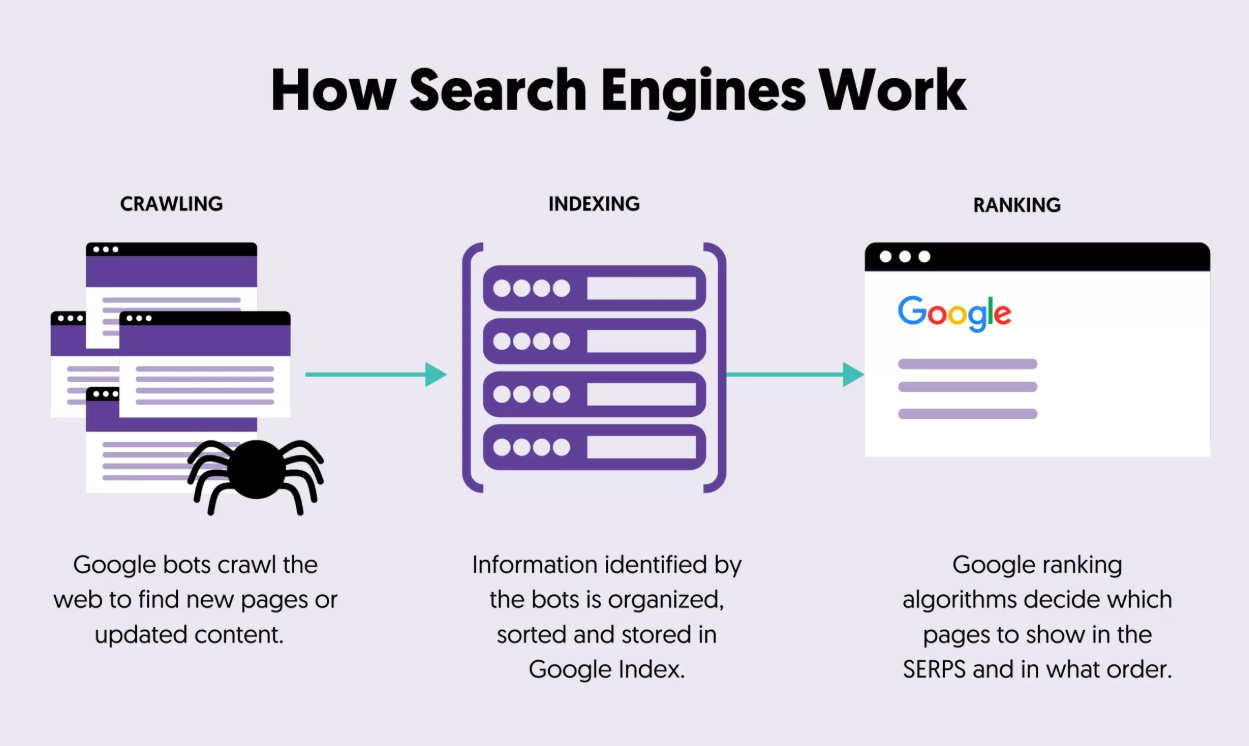
Lập chỉ mục là gì?
Sau khi một trang web đã được thu thập thông tin, đã đến lúc thêm trang web đó vào cơ sở dữ liệu.
Lập chỉ mục là quá trình công cụ tìm kiếm lưu trữ những thông tin được tìm thấy và “gắn thẻ” chúng. (Quá trình này phức tạp hơn thế một chút, nhưng hiện tại thì gắn thẻ vẫn hoạt động).
Hãy nghĩ về nó theo ví dụ về thư viện mà tôi đã đưa ra trước đó: Nếu một hộp sách các loại được gửi đến thư viện, chúng sẽ được sắp xếp, gắn thẻ và đặt vào các ngăn có liên quan:
- Tiểu thuyết
- Tiểu sử
- Tự truyện
- Lịch sử
- Khoa học
Giả sử bạn muốn học động từ tiếng Pháp. Bạn có thể vào Google và nhập truy vấn tìm kiếm “danh sách động từ tiếng Pháp”.
Công cụ tìm kiếm sẽ tìm kiếm trong cơ sở dữ liệu các trang phù hợp với thuật ngữ tìm kiếm đó: (trong vài giây)
Có nhiều yếu tố quyết định lý do tại sao các trang đó lại hiển thị theo thứ tự đó. Các yếu tố này thay đổi tùy thuộc vào công cụ tìm kiếm bạn đang sử dụng, ví dụ, các yếu tố xếp hạng của Amazon rất khác so với của Google (sẽ nói thêm về điều này sau).
Trước tiên, bạn chỉ cần hiểu rằng quá trình “lập chỉ mục” là linh hoạt và khi các trang web phát triển/thêm nội dung mới/xóa nội dung mới, nội dung đó sẽ được thu thập lại và lập chỉ mục lại để cung cấp kết quả có liên quan cho các truy vấn tìm kiếm.
Bạn có thể lập chỉ mục trang web của mình nhanh hơn bằng cách gửi sơ đồ trang web XML tới Google Search Console.
Tại sao một số trang hiển thị cao hơn những trang khác?
Như tôi đã đề cập ngắn gọn trước đó, các công cụ tìm kiếm (còn gọi là nền tảng tìm kiếm) hoạt động theo thuật toán xác định thứ tự xuất hiện của các trang. Đó là một loạt các phương trình dựa trên các yếu tố khác nhau giúp máy tính quyết định thứ hạng của từng nội dung.
Với Google, cách đơn giản nhất tôi có thể giải thích là thông qua khái niệm bỏ phiếu.
Về bản chất cơ bản, một trang web càng có nhiều “phiếu bầu” thì thứ hạng của nó càng cao. Để tôi giải thích chi tiết hơn bằng ví dụ thực tế.
Nếu bạn tìm kiếm “mua iPhone 17”, bạn sẽ thấy Thế Giới Di Động đang đứng TOP 1.
Điều đó có nghĩa là trong số tất cả các trang liên quan đến chủ đề đó, trang webTGDĐ có “nhiều phiếu bầu nhất”
Nhưng làm thế nào các trang web có được những “phiếu bầu” này ? Vâng… “Phiếu bầu” còn được gọi là liên kết ngược (hoặc liên kết ngoài ), nghĩa là khi một trang web liên kết đến một trang web khác, về cơ bản là họ đang “bỏ phiếu” cho trang web đó.
Ngoài liên kết, Google còn xem xét các yếu tố như:
- Mức độ uy tín, phổ biến của thương hiệu
- Chất lượng nội dung
…và còn nhiều yếu tố xếp hạng nữa.
Hãy nhớ rằng nhìn chung, một trang càng có nhiều “phiếu bình chọn” thì càng tốt và không phải tất cả “phiếu bình chọn” đều như nhau.










